关于机器(深度)学习的炼丹docker部署计划
计划始于docker,败于ssh远程(为什么远程使用ssh连接过服务器而连接docker中的容器就失败)
从conda虚拟环境到docker容器;环境灵活配置提升,可以快速地在别的服务器、不同设备、不通操作系统中,环境管理,然后炼丹跑代码
在家中台式电脑中创建docker环境
docker基本教程(知识)Docker 容器使用 | 菜鸟教程
Linux操作系统入门(知识)入门 Ubuntu操作系统(超详细,巨简单,小白必看)-CSDN博客
双系统教程(操作,暂时不用)Windows 系统下安装 Ubuntu 双系统详细教程(图文指南)_windows安装ubuntu-CSDN博客
- 等待解决
自己电脑上使用的是window子系统功能(知识)全网最全Win10/11系统下WSL2+Ubuntu20.04的全流程安装指南(两种支持安装至 D 盘方式)_win10安装wsl2-CSDN博客
Ubuntu lst 版本与普通版有什么区别(知识)什么是 Ubuntu LTS?和普通版本有什么区别? - 系统极客
切换用户权限(操作,已经解决)【Linux】ubuntu 切换管理员/普通用户指令,看这篇就够了!-CSDN博客
从不同系统中安装docker,既然从Ubuntu系统(window子系统或者用docker desk版)『Docker入门指南』- 详细安装与配置教程,助你起航容器化世界! - 个人文章 - SegmentFault 思否
在conda中打包虚拟环境并在docker部署,如何再开启远端联机,实现本地云端,主机炼丹,优势在于极大的灵活了部署问题,环境不同的问题https://blog.51cto.com/u_16213450/12773839
对于自己而言将会常用到的docker命令
运行进入交互界面(很重要:用于在images使用conda代码,拓展环境第三方库)
1 | # 交互式运行(进入容器内的bash shell) |
在容器中安装的包如何保存到images?(11月10日)٩(•̤̀ᵕ•̤́๑)ᵒᵏᵏᵎᵎᵎᵎ
重构容器就可以,基础用之前的容器
如何在远程(notebook)ipynb中使用docker的images来跑代码——使用ssh或者notebook?(11月10日)
出现无法连接,超时等问题
胎死腹中(11月11日)决定放弃ssh远程连接计划
开始转变,决定施行conda环境打包(环境同步),git代码托管同步(代码同步),以及对应环境变更安装指令的保存(三段灵活性,成长型同步)
思考感悟:上午搞了三个小时的问题,都不知道咋解决,主要两个问题太前沿的问题,ai不会,因为常常联网搜索的匹配程度太低不准确;问题没有解决的百分99的原因都是因为问的问题不够精准,要多用bing搜索引擎来,精准搜索得到答案。(gpt4-o1更好用一点)
docker_desktop + wsl2 (win11) + NVIDIA Container Toolkit安装 + tensorflorw_gpu_docker(快速docker部署容器,并且实现tensorflow gpu 加速)+jupyter lab +ssh远程连接、远程控制
重点内容(关于wsl2中的代理配置问题)
- 想法路线来源于tensorflow的 官方教程:为了简化安装并避免库冲突,建议您使用支持 GPU 的 TensorFlow Docker 映像
- 重点参考这位大佬
- 关于NVIDIA Container Toolkit安装-参考官方教程其实重点在于代理
重要命令(关于docker的运行,以及重构)
- 下面的命令:-p指定容器内的端口向外映射(外部端口:容器内部端口),–gpus指定all可见,-v挂载主机卷到容器内,-d 指定images
1 | docker run --gpus all -p 9060:8888 -p 9061:8889 -p 9062:8890 -p 2222:22 -v F:\polymer_ai:/app/pa -d a73de5acf455 |
高版本不兼容,我靠,搞了我一下午(解决容器内tensorflow_gpu加速)
关于为什么在docker拉取的tensorflow容器中python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"的gpu检测不到(nvidia-msi、以及nvcc –version却可以正确输出)?
- 参考官方文档
高版本容器创建后报错
- 步骤1:在容器内运行下面命令,检查cuda和cudnn的版本
1 | ls /usr/local/cuda/lib64/ |
例如我的输出:
1 | # cudnn 的版本8.9.6 |
- 步骤2:在官网查询,对应兼容版本Build from source | TensorFlow
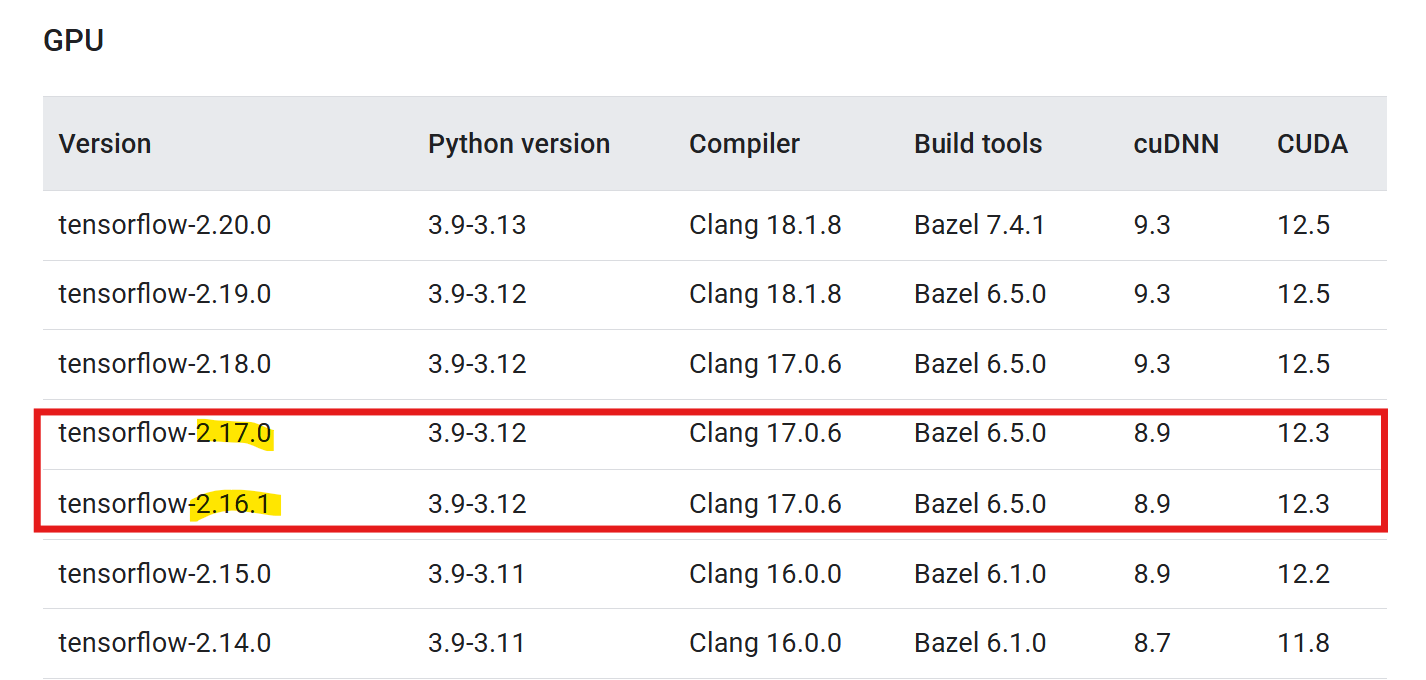
如上图所示tensorflow2.17.0 和 2.16.1 可以用
- 步骤3:pull 对应版本的tensorflow_docker,hub官网拉取对应版本的docker(需要魔法)tensorflow/tensorflow - Docker Image | Docker Hub
关于ssh远程连接docker的jupyter
根据最新的知识面了解到,ssh连接失败可能是不在一个局域网(超时),所以转向内网穿透领域
步骤1:打通宿主机和容器的网络,直接采用--nest=host网络共用模式
步骤2:成功实现trea中ipynb直接访问容器,内的jupyter映射出来的内核(直接也可以但是要用到转接技术)
步骤3:成功实现没有–nest=host的情况下,直接通过ssh命令连接容器内部,并使用root命令(宿主机中win中ssh连接不了,但用win的wsl可以连接)
步骤4:在远程机中安装wsl并尝试,在没有内网穿透下,连接宿主机
步骤5:实现宿主机与远程机的内网穿透,成功在各自的wsl内通过cpolar穿透,远程机连接到宿主机内部
步骤6:远程机通过ssh连接到宿主机后,再用docker命令进入容器内交互(这样就实现了,远程控制docker)
- 远程控制docker进程
步骤7:在使用ssh指令时将宿主机的localhost拉过来,成功使用得到
- 远程使用docker服务
重点讲一下6、7步是怎么形成的:docker是一种容器化技术,里面打包了我的机器学习深度学习的环境系统(利用docker(在Linux或者在docker_desktop中的)拉取,tensorflow官方在docker hub推送的image),并创建一个容器(在创建时使用的关键命令,涉及到启用gpus、启用端口投射将容器端口(冒号后面8888,指在容器内jupyter使用的端口)到宿主机的端口(localhost:9060));后在用cpolar+ssh的内网穿透技术,指定其他端口过来
- docker容器创建命令,将容器的jupyter服务8888发到宿主机的9060中
1 | docker run --gpus all -p 9060:8888 -p 9061:8889 -p 9062:8890 -p 2222:22 -v F:\polymer_ai:/app/pa -d 容器id |
- 在宿主机上配置好cpolar后,用以下ssh命令,将端口9060又转发到远程机上
1 | ssh -L localhost:9060:localhost:9060 root@cpolar隧道地址 -p 10954 |
炼丹计划终于大成了(2天半)
第零步:
笔记本电脑跑深度学习代码太慢(cpu太低,gpu不够),关于想利用docker容器技术,将代码部署到主机电脑(性能较好)并在主机上运行,实现主机跑代码、笔记本电脑写代码的炼丹大法。
于是开始了解并学习到有关容器docker的技术【关于为什么会想到docker因为之前电脑玩过deepseek的本地部署,但是后来发现本地部署的太笨了】,
并尝试把本地运行conda的虚拟环境的包需求列表导出,并引入Dockerfile的image构建文件中(学会了Dckerfile的命令句,以及利用这个文件构建docker的过程),后面发现因为库版本太具体,构建过程中出现问题,开始进入运行的容器内,手动安装需要的包(后面了解到容器暂停运行后并不会保存的image中,学会了从现有image中重新构建image),
之后也是成功实现docker环境的配置。问题又来了关于如何使用容器内的代码呢,当你把文件挂载进docker时,代码输出又开不见,且没有jupyter的问题,失去了交互性。
之后便开始尝试使用ssh来远程连接docker以及,使用docker内的环境。ssh搞了半天没用(后面发现其实要在一个局域网下才能用ssh来连接,以及docker的网络配置也不知)
之后便开始弃用docker,弃用远程连接,炼丹大法开始泡汤,但有趣的事,关于炼丹大法的事情并没有永远沉寂下去………
在放弃远程炼丹大法之后,由于课题依然要继续推进,便开始着手想着使用远程桌面加U盘的方法。便下载了Todesk软件,使用conda打包一整个环境传输后到主机电脑上解压展开,之后便成功完成了,在主机电脑相同的codna虚拟环境,之后发现xgboost和lightgbm算法通过简单的参数输入便成功使用上了gpu加速,代码运行速度直接打骨折,但运行到ANN(基于tensorflow的人工神经网络)不对了,gpu根本没有跑,运行速度依旧乌龟。于是开始从多途径了解tensorflow的gpu加速方法连接到在电脑上安装各种cuda驱动、CUDA、cndnn太麻烦且要考虑版本兼容问题,然后发现在tensorflow的官网上推荐,使用docker来部署tensorflow的gpu加速环境是最简单的。于是便开始了解docker的部署tensorflow-gpu方案。炼丹计划重新启动!
开始拉取tensorflow的镜像,(记得先配置轩辕镜像),这里建议拉取jupyter的版本,拉取之后在容器的交互页面中,发现tensorflow并没有没有找到gpu设备(卡住了半天😭),一直搞啊搞,主要是两个方向的问题:第一:cuda container toolkit下载不下来,curl的时候,一直无法连接,就算用镜像源也没用(后面用了魔法19yuan,也是重新又用上了)第二:安装好了,拉取镜像的时候,依旧不显示GPU,如何一直找原因,终于通过检查cudnn的版本发现兼容性问题(这个我真的没想到啊,想着拉取的tensorflow的docker应该兼容性是好的吧),开始查询官网的版本对照表,下载后,终于tensorflow检测到了gpu😎。
后面又了解到ssh内网穿透,可以远程连接,干脆一不做二不休,开始研究wsl(windows的linux子系统)、研究docker的运行命令关于网络端口的投射、 关于cpolar等等一些知识,后面终于通过重重问题困难,终于练就了炼丹大法,感谢这几天的自己😎,没有放弃偷懒🤣。
总结一下:《炼丹大法》涉及wsl(win下的Linux)基础命令指令、cuda container Toolkit的安装、win下docker的安装以及使用docker-desktop的镜像构建以及使用、ssh的命令以及使用、cpolar内网穿透的使用。
第一步:安装wsl,以及Linux的子系统(建议宿主机和远程机都安装),做好对应配置
第二步:安装docker-desktop,完成一些必要的配置,如确定wsl集成
第三步:在宿主机上安装cuda,以及利用wsl+魔法安装cuda container toolkit
第四步:用docker拉取tensorflow的gpu-jupyter版本的image,并通过命令运行容器
第五步:用cpolar+ssh打通,宿主机和远程机直接的网络以及端口
第六步:通过远程机的ssh连接后,用docker命令进入容器交互,下载缺少包环境。利用ssh连接是对应的端口转接,来打开docker容器的jupyter服务。
- 具体docker命令如下
1 | docker exec -it 容器id /bin/bash |